An open security harness that runs on your own models
By Kai Team · Published 2026-06-08

There is an uncomfortable trade at the heart of agentic security. To find the vulnerabilities hidden in a codebase, a tool has to read all of it, and for most of today's tools that means handing your most sensitive asset, the source itself, to a model running on someone else's servers. The security harness we are open-sourcing today removes that trade. It is model-agnostic, so you can run the whole pipeline on models you control, whether those are open-weight models on your own hardware or a model you have fine-tuned on your own code, and nothing about your repository ever has to leave your infrastructure.
That design choice follows from how we think the economics of software are shifting. Writing code keeps getting cheaper while verifying that the code is correct, safe, and worth shipping stays expensive, and the gap is widening as the models that generate code outrun anything that checks their work. Kai is built for the expensive half of that trade.
It is the team lead for an engineering org in which most of the code is now written by agents. Kai sits above the hands-on tools such as Cursor, Claude Code, Copilot, Codex, and Devin, and above the humans, holding the org-level context that none of them keep on their own. Four specialists divide up everything that happens downstream of generation, one for security, one for performance, one for coherence, and a memory layer the other three are built on, and a single rule governs all of them: the agent that proposes a change is never the agent that approves it.
This post is about the first of those specialists, the security harness, which is the piece we are releasing today. Pointed at a codebase, it pursues vulnerabilities the way a security team would, mapping the attack surface, forming hypotheses, writing proof-of-concept exploits, discarding the ones that fail to hold up, and reporting only what survives. There is no single prompt behind it and no fixed pipeline. Instead a team of agents works in parallel, coordinating through a shared findings store and adapting as the run unfolds, and the only signal it treats as real is exploitability, so a finding that cannot be turned into a working exploit never becomes a report.
Money is code
We proved it on smart contracts first because they are the cleanest place in all of software to test the claim that exploitability is the only signal worth trusting. In an ordinary application, a vulnerability sets off a long argument about severity, reachability, and blast radius, and a finding can sit in a backlog for months while people debate whether it is real. On a public chain that ambiguity disappears, because the contract is the money. The same code that encodes the business logic also holds custody of the funds, so a logic flaw is not a theoretical weakness waiting for the right conditions; it is a way to move someone else's balance into your own.
Three properties make the value of a finding impossible to wave away. The code is public and usually permanent, which means every attacker in the world can read it and a deployed contract often cannot be patched in place. The adversaries are real and financially motivated, since there is an immediate payout for anyone who succeeds. And the loss is irreversible, because once funds leave the contract there is no rollback and no support ticket to file. In that setting a vulnerability is worth exactly what an exploit can extract, denominated in dollars rather than in a CVSS band, which is why a proof that drains the contract on a sandbox fork is the strongest and least arguable form of evidence a security tool can produce.
This is the same standard the harness applies everywhere; smart contracts simply make it visible. A passing exploit that transfers tokens out of an unpatched contract is not a claim anyone can negotiate with, and that is the kind of evidence we wanted the harness judged on before we judged it on anything softer.
Here is the whole shape of it in under a minute: what we measure, how a run works, one real audit from start to finish, and the numbers on two public benchmarks, including the bar we did not clear.
What we measure, and what we leave out
We run the harness against two external benchmarks. evmbench is a set of real smart-contract audits with disclosed vulnerabilities, and CyberGym is a set of real C/C++ crashes drawn from OSS-Fuzz. On both, the question we care about is whether the agent can find the bug, which for a smart contract means naming the vulnerable function and the way to trigger it, then checking that against the audit's disclosed findings.
For C/C++ we keep two numbers deliberately apart. One measures whether the agent finds the defect, the other whether it reproduces the crash with a byte-exact input that trips the target. The first is the capability we are after, the second is a harder bar, and we report them separately rather than folding them into one figure that would read better while meaning less.
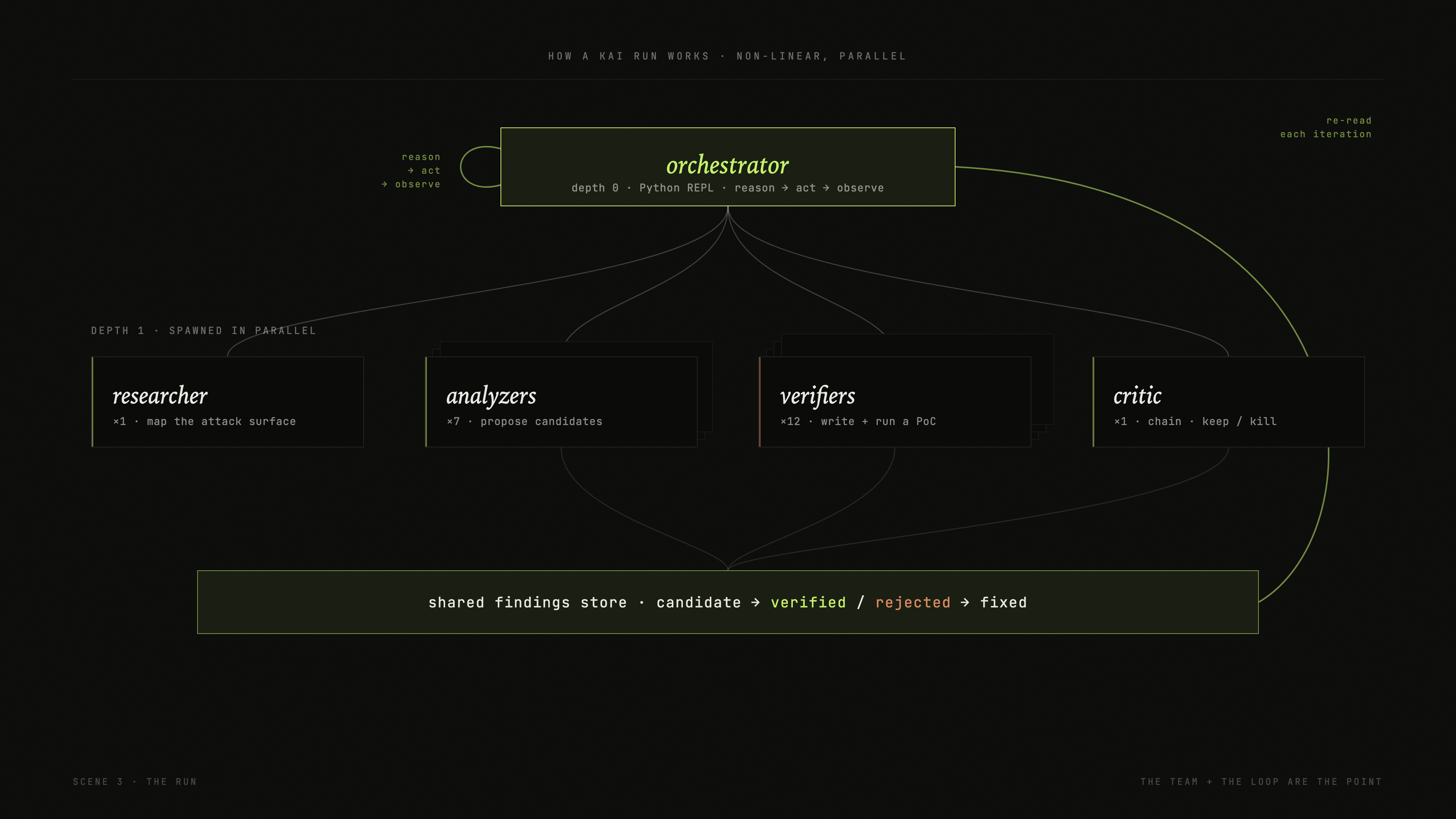
How a run works
A run is neither a single prompt nor a fixed pipeline. A root orchestrator works inside a Python REPL, reasoning and acting in a loop while it spawns specialized sub-agents that run in parallel:
- Researchers map the attack surface and decide where the run should apply pressure.
- Analyzers fan out across the code and propose candidate vulnerabilities.
- Verifiers each take a single candidate and try to prove it with a working proof of concept.
- A critic chains related findings together and discards the ones that do not hold up.
They coordinate through a shared findings store that the orchestrator re-reads and rewrites on every iteration, and it is that loop, rather than any one model in any one seat, that lets a run change course. It re-spawns analyzers when a lead looks promising, abandons dead ends, and promotes the candidates worth proving. Swap the models underneath and the shape of the run stays the same.
One audit, start to finish: Curves
Curves is an ERC-20 social-token platform that had already been through a professional security audit before we ever saw it. We pointed the harness at it anyway, and what follows is what came back, taken straight from the run rather than reconstructed afterward. The audit had disclosed four issues, and the researcher opened by singling out three areas worth pressure, namely the access-control modifiers, the fee accounting, and the presale whitelist. Seven analyzers then fanned out in parallel and raised fifteen candidate vulnerabilities, and twelve verifiers each wrote and ran a Foundry test against a single candidate in isolation to establish which ones were real.
The headline was a CVSS 10.0 access-control break. Inside Security.sol, the onlyOwner and onlyManager modifiers had been written as bare boolean expressions, with msg.sender == owner; and no require wrapped around them, so the expression evaluated, the result was thrown away, and the guard did nothing at all. The practical effect was that anyone could call functions meant only for the owner, and the verifier confirmed it directly when its tests testAttackerCanSetManager and testAttackerCanTransferOwnership both passed against the unpatched contract.
You can step through that one sub-investigation below, exactly as it came out of the run, from the researcher's lead to the analyzer that spotted the no-op guard to the verifier that proved it.
What turned a serious bug into a critical one was the critic chaining it forward. With onlyManager effectively disabled, an attacker can call FeeSplitter.onBalanceChange directly on any account, and doing so trips a second flaw in the fee accounting where userFeeOffset is updated without first crystallizing the pending credit. The attacker is then able to withdraw fees that were never theirs, so an access-control bypass becomes outright fee theft. Neither flaw is especially alarming in isolation, but together they add up to a way to drain the contract.
In the end the harness reproduced all four disclosed vulnerabilities: the fee-claiming bug in FeeSplitter, the honeypot rug enabled by a mutable presale whitelist, the unauthorized setCurves access, and the malformed-equate access break. It then went further and surfaced two issues the disclosure had not covered, a reentrancy in withdraw and a token-address confusion in deposit, both rated critical and each carrying its own passing exploit. Eight candidates were verified in total, while the rest were either de-duplicated or rejected, including one proof of concept that would not compile and two that only worked as steps inside a larger chain rather than on their own. The whole audit took five hundred and forty-four agent iterations and eighty-five minutes, most of that time spent running in parallel. Every finding it kept arrived with an exploit that runs against the unpatched code, which is the standard the harness holds itself to in place of a list of suspicious lines.
Results
We test the harness across several models on the full evmbench set and a randomly selected set of tasks from CyberGym, since the numbers shift depending on which models sit in which seats. The figure below shows where they land, along with the split between finding a bug and reproducing it.
On the CyberGym tasks, the harness can run for three or more hours, so we have not completed a full run yet. You can run all of these benchmarks yourself to verify the results on any task.
On the full evmbench benchmark, which spans 40 tasks and 120 disclosed vulnerabilities, the harness scored 65.7% using Claude Opus 4.6 as the orchestrator, MiniMax-M2.5 for the sub-agents and setup, and GPT-5 as the detection judge. A separate ten-task run on a newer spread matched 24 of the 28 disclosed vulnerabilities, with clean sweeps on curves, abracadabra-money, canto, ethereumcreditguild, pooltogether, and althea, and the Curves walkthrough above is drawn from that run.
On CyberGym, where the target is reproducing a crash in C and C++, the harness found the defect in 9 of 15 tasks when the bug was described, and in 1 of 10 when it was given nothing but the source. It produced a byte-exact crashing input only once. That last number is low by design rather than by accident, because on this benchmark we deliberately withhold both payload-creation tooling and any guidance on constructing the crashing input, so strict reproduction understates what the harness finds in practice. We would rather publish the weak number than quietly retire the benchmark.
What we're releasing, and why
The release is the harness itself, which means the orchestrator, the four sub-agent roles, the shared findings store, and the verification loop that together turn a language model into a security team. Because it is model-agnostic, you decide which models sit in those seats. You can point it at frontier APIs when you want maximum capability, or, when the code is too sensitive to leave your network, you can run the entire pipeline on open-weight models on your own hardware or on a model you have fine-tuned on your own repositories, in which case nothing about your codebase is ever shared with anyone. For a tool whose whole job is to read your most sensitive source and search it for ways to break in, that last property is not a nice-to-have; it is the point.
We are open-sourcing the harness for the same reason its benchmark numbers move with the models underneath it. The capability does not live in any single model but in the team and the loop around it, which is the part you cannot recover from a better prompt, and the part we would rather see improved in the open than kept behind a wall. You supply the models and the codebase, and the harness does the rest.
Get it: github.com/firstbatchxyz/kai-security · install and quickstart in the README.
Takeaways
Three things are worth carrying away. On smart-contract audits the harness detects most of a disclosed set, 65.7% across the full 40-task evmbench benchmark, and on individual audits it regularly turns up issues the original disclosure missed. On C/C++ it finds the defect far more often than it reproduces the crash byte for byte, and every one of those figures depends on the model spread sitting underneath it. The most important point is the one the open-source release is built around: the capability comes from the parallel team and the feedback loop between its agents rather than from any single model, which is why we are putting it in your hands to run on whatever models you trust, including ones that never let your code leave your own machine. Point it at your codebase, try to break it, and make it better.