You're Just Not Re-Searching Hard Enough
Vibe coding went mainstream. You describe what you want, an LLM writes it, you iterate. That's powerful, and it changed how people build software. But here's what we think most people are missing: that was step one, generation. Step two is research. Taking code that already works and discovering implementations that are fundamentally faster, not by asking a model once, but by searching for them.
This is a different kind of problem entirely. When you generate code, you're sampling from a distribution. When you research code, you're exploring a space. You're running experiments. The question shifts from "can AI write this?" to "what's the best version of this that exists, and can AI find it?"
Here's what that actually looks like. You tell the system what "better" means for your codebase. Maybe that's inference speed. Maybe it's memory. Maybe it's throughput on a specific pipeline. Then you walk away. An agent spins up hundreds of candidates, evolves them in parallel, evaluates each one against your criteria, and by the time you come back, it's found things you wouldn't have thought to try. Your job isn't to explore the solution space anymore. Your job is to judge what the search found.
People have started calling this vibe research, and the name fits. You set the objective, the machine runs the search, you evaluate the results. It's what vibe coding wishes it was when the stakes are performance.
The question is: what kind of research is actually good enough to beat an expert?
What Research Looks Like When the Substrate Is Code
Here's the basic insight. Take a program. Create a population of variants. Evaluate each one against a fitness function (runtime, throughput, memory, whatever you care about). Keep the best, mutate them, recombine them, repeat. This is how nature designs everything from enzymes to neural architectures.
The problem has always been infrastructure. Coordinating multiple LLM providers to generate intelligent mutations, managing populations of candidate solutions, running evaluation harnesses at scale, tuning exploration versus exploitation: this has been the domain of well funded research labs with dedicated teams and significant compute budgets. DeepMind has been doing it. A few frontier labs have been doing it. You probably haven't, because the barrier to entry was enormous.
We built Kai Evolve to remove that barrier entirely.
Kai Evolve is an autonomous optimization agent. You point it at a codebase, describe what you want to improve in plain language ("improve inference runtime," "reduce memory allocation"), and it runs hundreds of iterations through evolutionary search to find better implementations of your code.
Not a single LLM pass. A full evolutionary process: populations of candidates, intelligent mutations generated by frontier models, selection pressure from your own benchmarks, and convergence detection that knows when to stop.
The Details That Actually Matter
The naive version of this idea doesn't work. You can't just randomly mutate code and hope for the best. Several hard problems had to be solved, and they're worth understanding because they're the difference between a toy demo and something that actually beats human experts.
Convergence collapse. The population finds something decent and just keeps making tiny variations of it. Every candidate starts looking the same.
We built novelty filters that penalize similarity, forcing the search to keep exploring structurally different approaches even when it finds a good local optimum. This is the difference between finding a 1.2x speedup and a 4x speedup.
Model selection. Not all LLMs are equally good at all types of mutations. Some models excel at algorithmic restructuring. Others are better at low level memory optimization.
Kai Evolve uses intelligent model sampling that learns which provider performs best for each type of task and adapts its selection strategy over the course of a run. You don't configure this, it figures it out.
Knowing when to stop. Evolutionary search can run forever. You need early stopping and convergence detection that recognizes when the fitness curve has plateaued and further iterations are unlikely to yield improvement. Otherwise you're burning compute for nothing.
Cross pollination. Kai Evolve maintains multiple candidate pools and uses migration between them. A promising approach discovered in one lineage can jump to another, combining ideas that evolved independently. This is how you avoid the monoculture problem in evolutionary systems.
All of this runs on a scaled inference runtime that distributes work across multiple frontier LLM providers, coordinates hundreds of iterations, and manages the full lifecycle from initial population seeding to final solution extraction.
53.3% Opt@1. Number One on the Leaderboard.
On its first public evaluation, Kai Evolve scored 53.3% Opt@1 on the Global Software Optimization (GSO) benchmark, placing #1 on the leaderboard ahead of every frontier model tested.
Some context on what this means.
The GSO benchmark gives AI agents a program with a performance test and asks them to produce a faster version. Opt@1 measures the fraction of tasks where a single attempt achieves at least 95% of the speedup that a human expert developer produced. This is a high bar. You're not just being compared to the baseline; you're being compared to what a skilled human already optimized by hand.
Kai Evolve was evaluated on 30 optimization tasks spanning real repositories: NumPy, Pandas, Transformers, Tokenizers, Pydantic, Tornado. On 29 of 30 tasks, it produced a measurable speedup over the baseline. On 6 tasks, it exceeded the optimization that the human expert produced.
The next best system on the official leaderboard is Claude 4.6 Opus with OpenHands at 33.33%. That's nearly 20 points behind.
We didn't expect that gap to be this large. Evolutionary search with intelligent model selection appears to be a fundamentally stronger approach to code optimization than single pass generation, even from the most capable frontier models. The search finds things that a single forward pass simply cannot.
What Vibe Research Looks Like in Practice
You connect a GitHub repository and start an evolution in four steps. Define a goal in plain language. Select which files are candidates for mutation. Review auto generated evaluators (Kai Evolve proposes these based on your codebase; you verify and adjust). Hit run.
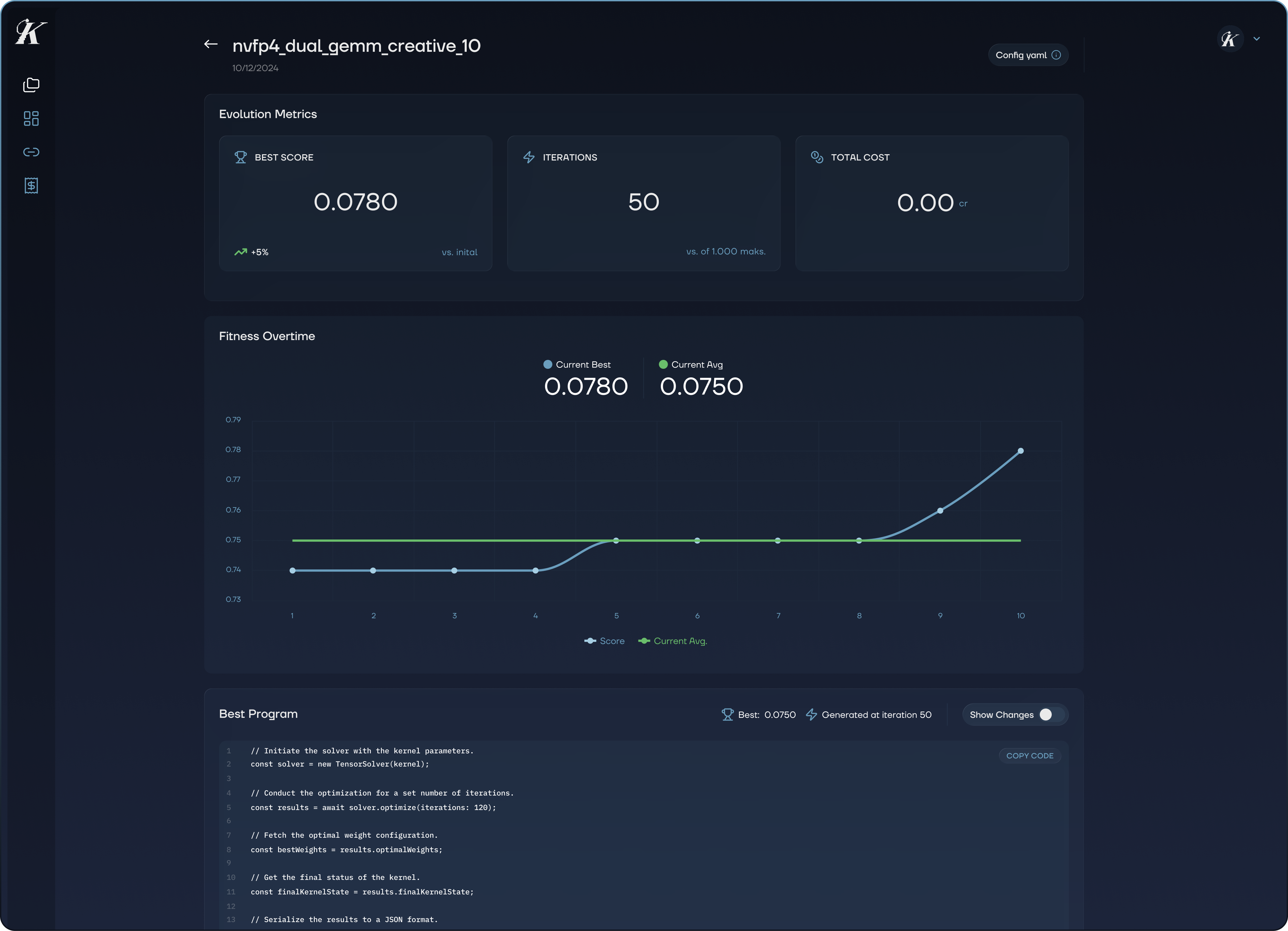
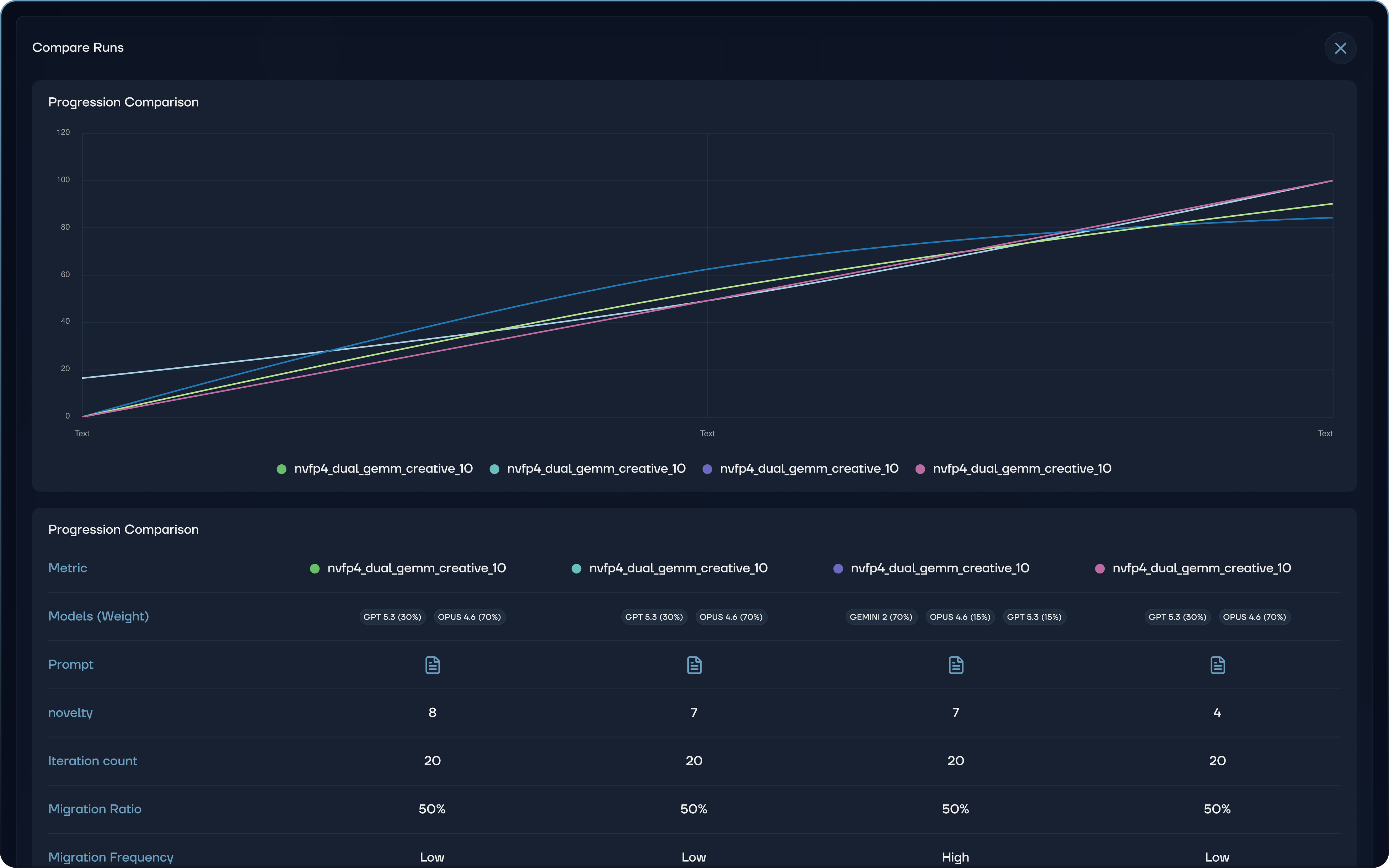
Then you watch. The interface shows a live fitness curve tracking the best score and population average across iterations, the current best candidate with a full diff of changes, cost, and convergence status.
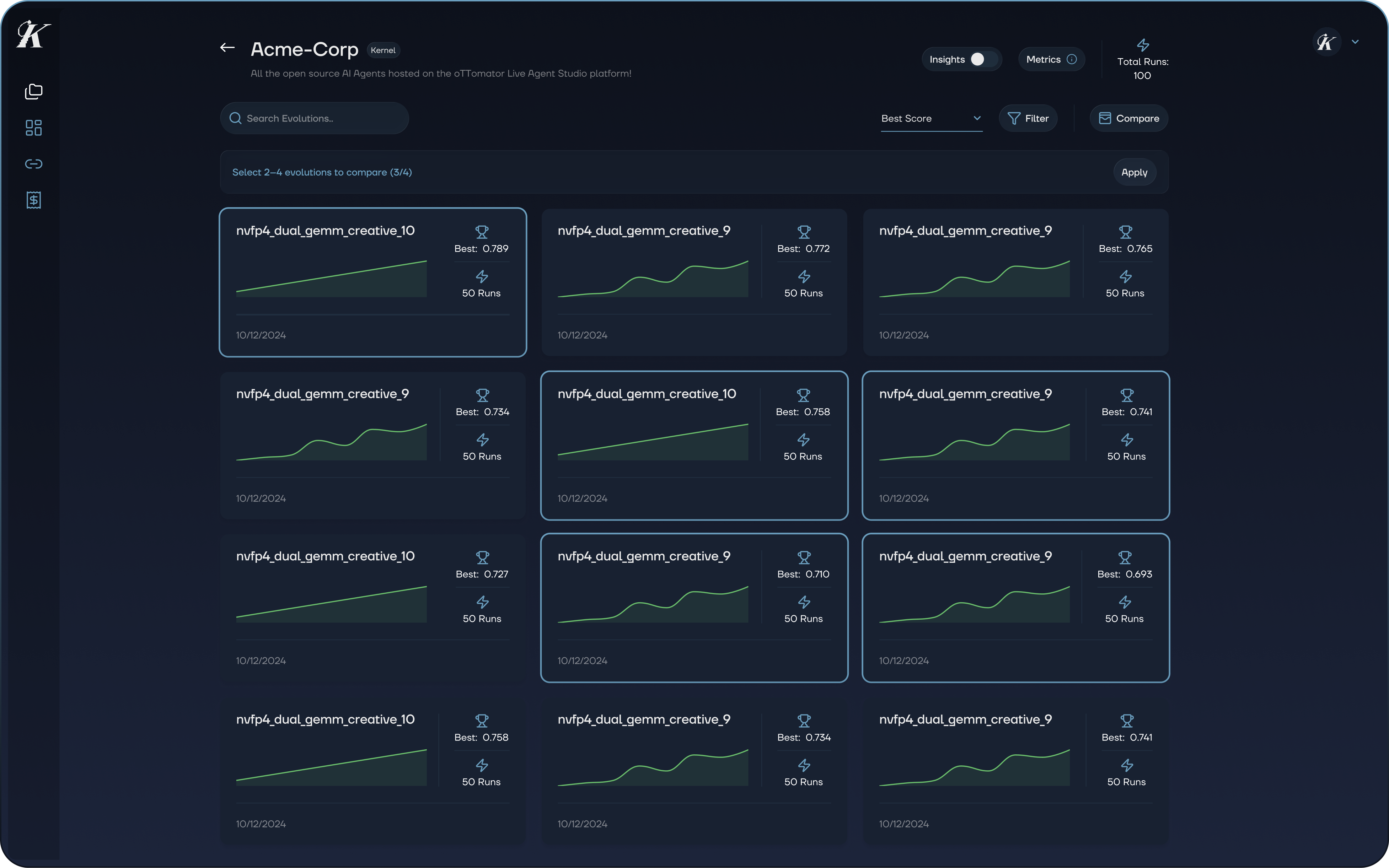
Here's where it gets interesting. You can run multiple evolutions with different configurations and compare them side by side, up to four at a time, with progression curves overlaid on a single chart. A detailed comparison table breaks down each run's model weights, novelty scores, iteration counts, and migration parameters. You don't just see which configuration won. You see why it won.
A solo developer optimizing a data pipeline. A startup squeezing latency out of a critical inference path. A student exploring algorithmic improvements for a thesis. The same evolutionary approach that required a team of ML engineers and a compute cluster is now a four step setup with a clean interface.
Why This Matters Beyond the Benchmark
There's something deeper happening here that's worth paying attention to.
For most of software's history, performance optimization has been bounded by human intuition. We can only try approaches we can think of. We explore the solution space one branch at a time, guided by experience and pattern matching. The search is narrow and slow.
We're entering a period where the bottleneck in software isn't writing code or even designing systems. It's finding the best version of what you've already built. And that's a problem that gets better with compute, not with headcount. Every dollar you spend on vibe research explores more of the solution space. Every iteration compounds. The economics of optimization are about to invert: it will cost less to search for the best implementation than to pay a senior engineer to guess at it.
Think about what that means at scale. Not one team optimizing one hot loop. Every codebase, continuously evolved against its own performance criteria, getting faster in the background while people focus on building new things. The performance floor of average software rises. The gap between "shipped" and "optimized" closes. Software gets faster not because developers get better at optimization, but because optimization becomes something you run, not something you do.
Kai Evolve is available now at kai.dria.co/evolve. The full benchmark results and per task breakdown are on our benchmark page.
Try it on the code you've already optimized by hand. The results might surprise you.